












收起
微信扫码看直播
活动内容收起
大数据时代,越来越多的传统企业开始做数字化转型,互联网公司对大数据存储、实时分析和处理的需求一直居高不下。企业该如何面对数据与应用的种种挑战?
Apache CarbonData 是一种新的融合存储解决方案,利用先进的列式存储、索引、压缩和编码技术提高计算效率,从而加快查询速度,万亿级数据秒级响应,目前已在 20+ 企业生产环境上部署应用。例如一个规模较大的场景,支持单个表 3PB 数据(超过 5 万亿条记录)上明细数据分析,响应时间小于 3 秒!而大数据统一分析引擎 Apache Spark 在近日也推出 2.4 版本,为我们带来了众多的主要功能和增强功能。
本次 Meetup 集合了来自 Databricks、华为及 Intel 的重量级嘉宾,这些嘉宾将以丰富的技术经验与独到的技术见解,为我们带来数据存储与计算效率方面更深入的技术剖析。
活动日程:
本期主题有:
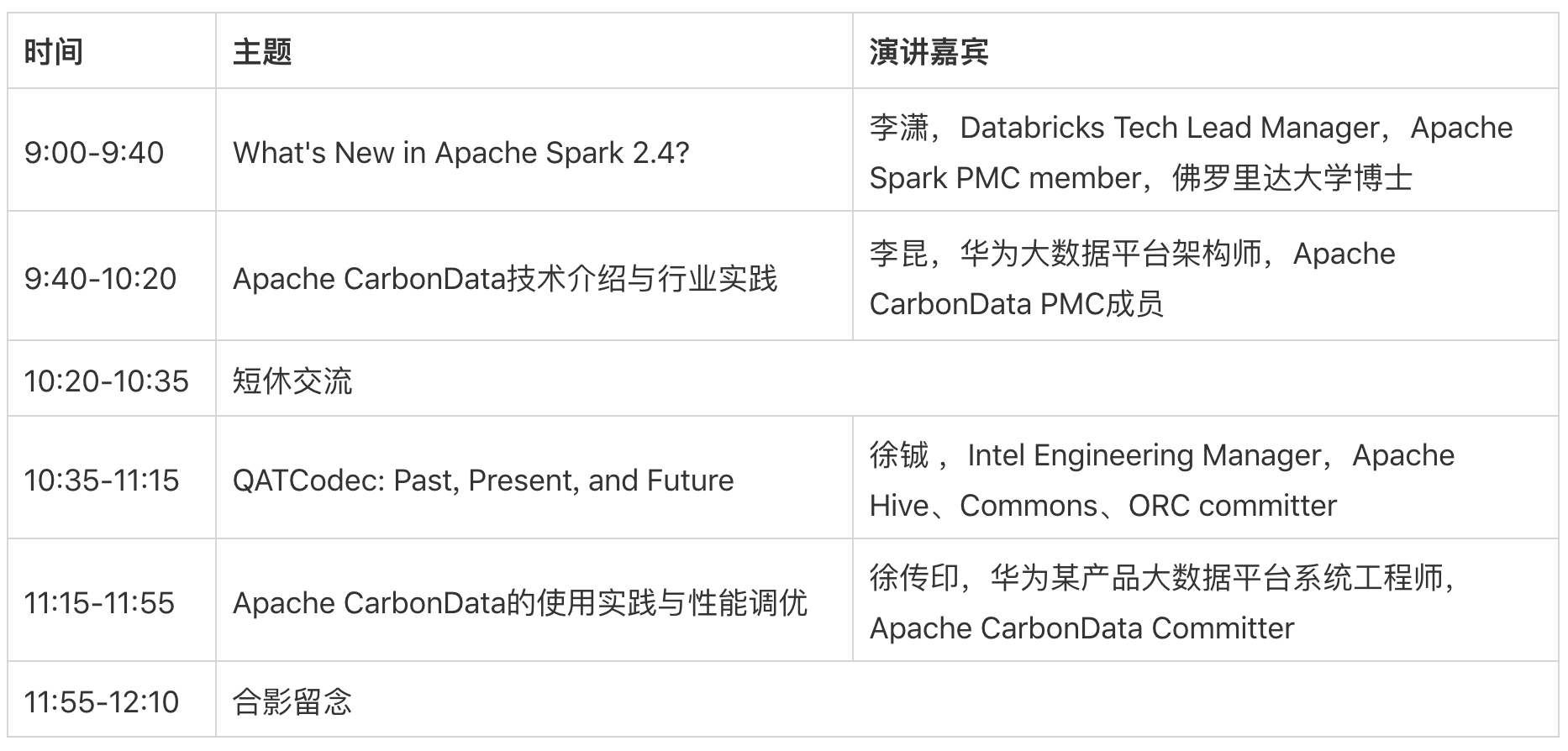
1. What's New in Apache Spark 2.4?
主题介绍: This talk will provide an overview of the major features and enhancements in Spark 2.4 release and the upcoming releases and will be followed by a Q&A session.
The Apache Spark 2.4 comes packed with a lot of new functionalities: new barrier execution mode, flexible streaming sink, the native AVRO data source, PySpark’s eager evaluation mode, Kubernetes support, higher-order functions, Scala 2.12 support and a lot of other improvements.
分享嘉宾:李潇,现就职于Databricks,专注于Apache Spark的开发和建设。他是Apache Spark项目管理委员会成员。本科毕业于南京理工大学,后在佛罗里达大学(University of Florida)获计算机博士学位, 曾就职于IBM,获发明大师称号(Master Inventor),在数据处理领域发表专利十余篇。(Github: gatorsmile)
2. Apache CarbonData技术介绍与行业实践
主题介绍:针对海量明细数据的分析场景,全方位介绍CarbonData的架构、技术原理、适用场景以及最佳实践。
分享嘉宾:李昆,大数据平台架构师,Apache CarbonData PMC成员,长期从事电信、企业、IoT数据解决方案、数据分析和可视化统研究和研发工作。近年致力于大数据和AI技术创新,参与Apache Hadoop、 CarbonData、Spark、Flink等多个开源项目。
3. QATCodec: Past, Present, and Future
主题介绍:随着业务的持续增长,针对计算密集型和高I/O的大数据解决方案对于企业和基于云的数据中心变得越来越重要。大量的数据被压缩来减少存储I/O和网络传输的压力,QATCodec项目利用了Intel QuickAssist技术来使用额外的硬件加速器来offload CPU压缩计算并进行加速。在这个演讲中,我们将介绍一些核心的使用QATCodec来加速大数据计算的场景。
分享嘉宾:徐铖,来自于Intel大数据技术团队,专注于大数据分析领域, Apache Spark、Parquet contributor, Apache Hive、Commons、ORC committer。他致力于在大数据核心组件上基于Intel平台进行优化以及帮助Intel的客户为他们的业务提供大数据解决方案。
4. CarbonData的使用实践与性能调优
主题介绍:2018年以来,CarbonData发布了多个稳定版本(1.3.x, 1.4.x, 1.5.x),引入了大量新特性,同时性能进一步得到提升。如何理解和使用好这些特性,发挥CarbonData的特长是摆在CarbonData使用者面前的一道难题。目前 CarbonData 已经在 Huawei SmartCare 产品中作为详单查询引擎处理超过100TB/天的数据,并且在将来会进一步作为数据仓库来处理汇总和报表相关的业务。本议题以自己项目组在数据平台中使用CarbonData的经历,讲解如何使用和调优CarbonData。
分享嘉宾:徐传印,现任华为公司SmartCare产品大数据平台系统工程师。2013年加入华为,长期从事大数据技术在电信领域详单查询、数据仓库中的研究、优化和应用。2017年5月份开始接触CarbonData,重点提升了CarbonData的数据入库性能,并在2018年5月份成为社区Committer。
为了方便大家线上交流,本次 Meetup 提供微信群,报名的小伙伴可扫描以下二维码(微信号:xu601450868),添加好友,备注:Meetup,拉你进群~

大会直播连接:http://zhibo.huaweicloud.com/watch/2590022

活动标签
最近参与
-
潘丽报名
(6年前)
-
霍去病报名
(6年前)
-
 陈金武 德恩资本收藏
陈金武 德恩资本收藏(6年前)
-
navy报名
(6年前)
-
 萧萧信息系统收藏
萧萧信息系统收藏(6年前)
-
df收藏
(6年前)
您还可能感兴趣
您有任何问题,在这里提问!
下载App观看回放

扫码小程序报名
联系主办方
联系电话:





